Problem: Design a large scale autocomplete/typeahead suggestion system like the suggestions one gets when typing a Google search. Let's see what are the requirements here:
- For a Google-like scale of about 5 billion daily searches, which translates to about 58 thousand queries per second. We can expect 20% of these searches to be unique, this is, 1 billion queries per day.
- If we choose to index 1 billion queries, with 15 characters on average per query and 2 bytes per character, then we will need about 30GB of storage to host these queries.
Please note that we will cover only the following:
- Only English locale
- Number of suggestions: 5
- Sorted suggestions according to rank
We will talk about the trending and personalized suggestions but won't cover it totally.
Design:
Let's see what are the service requirements we have:
- Highly available
- High Performance: Client should get suggestions in < 100 ms
- Scalable: Should serve a large number of requests while maintaining the performance
If you see there are two main components in the design:
- Suggestion system: Serves the autosuggest requests for the top phrases of a given prefix
- Assembler system: Collects user searches and assembles them into a data structure that will later be used by the suggestion system.
So for now, our system looks something like following:
Now let's deep dive into every component that we have:
1. Suggestion system:
Let's first understand what Dats Structure we are going to use to store our phrases so that it will take less storage and also quickly give the top phrases given a prefix.
Whenever we hear prefix, we automatically think of
Tries. Using Tries we can save lots of phrases using very less storage and also we can find a word in a Trie in O(n) where n is the length of word which is I think is very fast. But the Trie which I have used in the above link won't work as is for us. We need to make some changes there.
1st change is we need to give a rank to phrase in order to return "top" phrases. That means we need to store a rank in the TrieNode so now our TrieNode will look like:
public class TrieNode
{
public long? Rank { get; set; }
public TrieNode[] Childrens { get; set; }
}
So now we are ready to serve our request which is given a prefix return the top 5 phrases from the Trie. Here are the steps which we can follow to serve such request:
- Go to the prefix ending node using the prefix characters. Call it Prefix Node.
- Apply DFS to all the sub trees of Prefix Nodes to get all the phrases.
- Sort all the phrases based on their Rank.
- Return the top 5
Let's calculate its time complexity. It will be O(Prefix length) + O(number of nodes in the tree with root as Prefix Node) + O(number of phrases * log (number of phases))
Given that we need to serve these requests in < 100 ms, the above approach won't work for us because of the time complexity of this approach.
Here comes the 2nd change in the TrieNode. What we can do is, we can apply some preprocessing and store the Top 5 phrases on each node.
public class TrieNode
{
public long? Rank { get; set; }
public Phrase[] TopPhrases {}
public TrieNode[] Childrens { get; set; }
}
Phrase class will look like:
public class Phrase
{
public long Rank { get; set; }
public string PhraseText { get; set; }
}
Now once we have stored these phrases on TrieNodes. Our flow will become something like:
- Go to the prefix ending node using the prefix characters. Call it Prefix Node.
- Return the Phrases (Just PhraseText not rank) stored at the Prefix Node.
Now if you see the time complexity will be O(prefix length) which is good. We are done with our core logic of generating suggestions. Now let's see how are suggestion system is looking like:
All good till now. But now let's start working on our requirements.
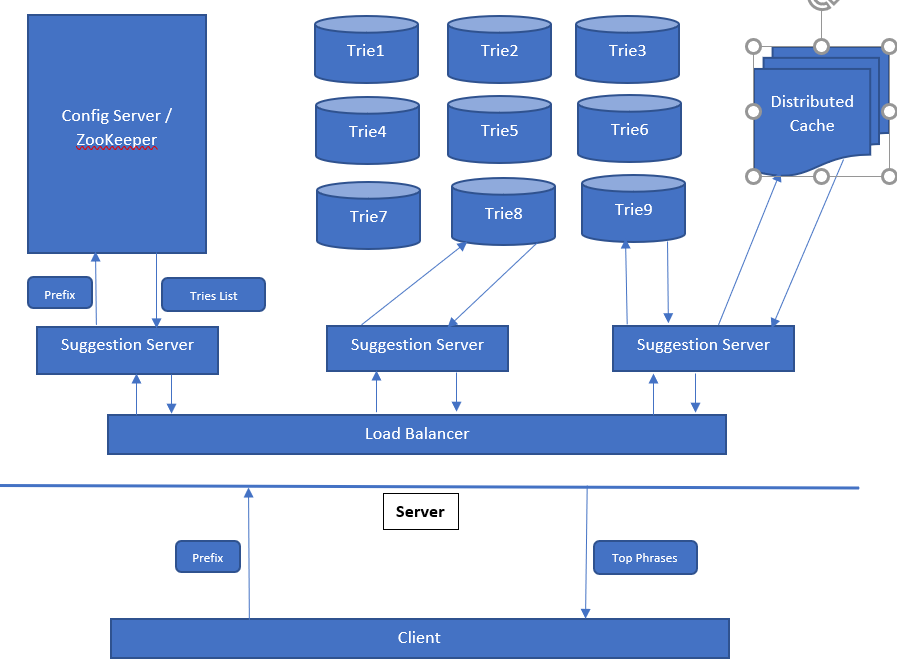
1. Availability: We just can't rely on one Trie node to serve all the requests. What will happen if Trie node crashes. The whole system is down. To solve this issue, we can have multiple exact replicas of the Trie.
2. Data Size: There could be billions of phrases that means one system is not suffice to accommodate this much of data in the memory. What we can do is we can divide this data into multiple Tries. Say phrases starting from a - h will go to Trie1, Trie2 and Trie3 (replicas), i to p will go to Trie4, Trie5 and Trie6 and rest of the phrases will be stored in Trie7, Trie8 and Trie9. Please note that it is not ideal distribution but just a hint that we need to divide the data.
3. Now we have divided the data, the suggestion server needs to know given the prefix which Trie to connect to. We can hardcode this info in the suggestion server but it will be a bad solution as this can be changed over the time then we have to keep changing this logic in suggestion server. This tells us that we should have another service which will manage this configuration data but if you see this new service may become a single point of failure so we need to be very careful while designing this service. Instead of creating our own service we can use
Apache Zookeeper here to store this config data. ZooKeeper provides a centralized service for providing configuration information, naming, synchronization and group services over large clusters in distributed systems. Please note that ZooKeeper is highly available and is very good with many reads and less writes which is exactly our scenario.
4. Scalable: Given the traffic, 58K QPS, we know that a single server can't serve all requests efficiently and even reliably. That means we need to have multiple suggestion servers which are horizontally distributed and obviously we need to have load balancer to balance the loads among these servers.
5. Performance: We have seen that our core logic of getting the top phrases is very fast but still getting which Trie to connect to and then get the phrases from that Trie, can be expensive some time. What we can do is we can use a distributed cache like Redis cache to store the frequently used / most recently used prefixes and the related to phrases. Now we can quickly retrieved these phrases from the cache itself instead of going to a full cycle of retrieval. We can use
cache-aside pattern to maintain this cache.
Now we have taken care of all our requirements, let's see how our suggestion system looks like:
So that's all about designing the Suggestion system. I think the flow should be clear by now but I am still writing the steps here:
- Client sends the request with a prefix to Load Balancer.
- Load Balancer choose a suggestion server randomly/ round robin / depends on load.
- Suggestion server first query cache with the prefix. In case of cache hit, It just returns the phrases. In case of cache miss go to step 4.
- Suggestion server query ZooKeeper with the prefix to know which Trie to connect to. Gets the list of Tries.
- Suggestion server chooses a Trie randomly from the list of Tries it got at step 4.
- Suggestion server query the selected Trie at step 5 to get the phrases.
- Write {prefix, phrases} into cache asynchronously.
- Returned the phrases to client.
That's all for Suggestion system. There are still few optimizations we can do here:
- We can cache some data to CDNs
- While sending the top phrases for prefix say mi, we can also send top phrases for prefixes like mic, mit, micr etc. which we think are frequently used or based on some other parameters. Client can save these results in its local cache and in case of cache hit, it can get the result from the local cache itself.
2. Assembler system:
Assembler system collects the search data and using this data it builds the Tries. As for now flow looks like:
Let's go into the details.
1. Given the traffic, obviously we will be needing many assemblers and a load balancer to balance the loads among them.
Here load balancer are not going to use any random technique to manage loads among assemblers like round robin or based on loads, instead
load balancers are going to use Hashing and more specifically Consistent Hashing for routing the requests. Let me tell you why? We actually don't want assembler to just take a single search query and update the Tries or a intermediate Database every time. This will cause first huge load and second we will get many redundant nodes in tries which we ultimately remove it from Tries. We definitely want to do
some preprocessing to make sure we are adding right data to our productions Tries.
2. Now let's say one of the assembler finally get the request containing search query and a weight. What it does that it keeps aggregating these queries and keep adding the weights (in case of same search query) and say after some time (say 15 minutes), flushes this data into a No-Sql Database like MongoDB. Here is the schema of the table:
|
Search Query
|
Date
|
Weight
|
|
Microsoft
|
Jan 4, 2021
|
1765
|
|
Microsoft
|
Jan 5, 2021
|
1876
|
|
Microsoft
|
Jan 6, 2021, 10 AM
|
765
|
|
Microsoft
|
Jan 6, 2021, 11 AM
|
1623
|
So if you see entries in the above table what we are doing here is we are adding a row per term on hourly basis. If Microsoft comes at say 10:15 AM and then 10:45 AM with weight say 400 and 365. What will happen assembler will flush the data on 10:15 AM and make an entry:
Microsoft | Jan 6, 2021, 10 AM | 400 |
Now 10:45 AM Microsoft came again so now when assembler flush the data, the existing entry will be modified and the weight will become 400 + 365 = 765:
Microsoft | Jan 6, 2021, 10 AM | 765 |
but if Microsoft comes at 11:10 am, we will add another row in the table. That's how the Assembler will work.
3. If we have entries per term per hour, there will be a huge number of records in our Database and we might not want it. What we can do is we can have timer jobs / cron jobs which will convert these hourly data into daily data by summing up the weight. Like you have seen in the above table except for the current day rest of the entries are on day basis. We can also remove many entries if weight of a search query is below threshold as anyway this will never come in the top results.
We can have this data in our databases as long as we want but do we really need old data. In most cases the rank of the results depends on the how recent it is. We can remove all the rows which are older than 30 days. Some Database provides such functionality if not we can use timer jobs to accomplish it.
This Database can also help building the Tries in case all the Tries are down for a certain range. In most cases it is not required at all.
4. To build the Tries, we can have different services say TrieBuilders. We can create TrieBuilder depends on the number of ranges defined in the ZooKeeper to avoid the concurrency issues. Basically only 1 TrieBuilder will update/create the Tries for a particular range. Like only one TrieBuilder will update the Tries Trie1, Trie2 and Trie 3 for the prefixes in range a - h.
5. What TrieBuilder does is it checks the Database for its range say after every 30 minutes and update the existing Trie or build a new Trie and replace the older Trie with the new one whichever is more efficient. TrieBuilder also rank each search query based on how recent it is and other parameters. If you were wondering why we are having a Date column in our Database, I think you know now why we are keeping the time of a search query on our Database.
The only problem here is What if a TrieBuilder crashes. To solve this problem we can have a secondary TrieBuilder attached to every TrieBuilder which is an exact replica of primary.
So now if you see our assembler system will look like following:
That's all about our Assembler system.
Additional Features:
Now let's talk about the trending searches, I think our system will cover it as trending searches are which are being searched recently a lot.
For personalized searches, what we can do is we can maintain the user search history in the cache with keys as prefixes and value is user search queries. Once we get the default suggestions from our current system, we can also get the top suggestions from user search history cache. In the end we will merge the results and return it to the client. One thing which we need to take care of is how much search history we can save it in the cache. Please also note that we need to have another microservice say UserSearchHistory service which will manage search history and we can call our default service and this new service in parallel to get the result asap.
With that I think we are done with the discussion about the system design of Auto complete feature.




No comments:
Post a Comment