Problem: Design a highly scalable public discussion forum like reddit, quora or Stack Overflow. Here are the features that needs to be supported:
- Post questions / news to public
- Comments on existing posts
- Upvote/downvote posts or comments
- Feed of most popular posts.
Requirements:
Functional requirements:
- This is browser only application.
- A logged in user only can post, comment and vote.
- A post contains following:
- Title
- Tags
- Body containing text and image
- Any user (logged in) can comment on any post.
- Comments are shown as list in descending order by time.
- Use can delete his/her own comments or posts.
- Any user can vote any post or comment.
- A user's home page contains the top popular posts in the last 24 hours where:
- Popularity = Upvotes - Downvotes
Non functional requirements:
- Scalabilty: Millions of daily users.
- Performance: 500 ms response time 99 percentile.
- Availability: Priority to availability over consistency as it is ok if the user won't see the latest data.
- Durability: Have posts and comments till the user doesn't delete it.
Design: Now that the requirements are clear. We will start with our design.
Step 1: API design:
We will first try to come up with the Rest APIs as per our functional requirements. For this we need to first identify what are the entities in our system and try to map those to URIs
- Users:
- /users
- /users/{user-id}
- Posts:
- /posts
- /posts/{post-id}
- Images
- /posts/{post-id}/images
- /posts/{post-id}/images/{image-id}
- /posts/{post-id}/comments/{comment-id}/images
- /posts/{post-id}/comments/{comment-id}/images/{image-id}
- Comments
- /posts/{post-id}/comments
- /posts/{post-id}/images/{comment-id}
- Votes
- /posts/{post-id}/vote
- /posts/{post-id}/comments/{comment-id}/vote
Let's see how the post looks like: (response of GET)
{
post_id: string
title: string
tags: List of strings
user_id: string
upvotes: int
downvotes: int
body: json
}
Let's see how the comment looks like: (response of GET):
{
post_id: string
comment_id: string
body: json
user_id:
upvotes: int
downvotes: int
}
Now that we know the entities and URIs, its time to assign the HTTP method which wll ultimately results ino our final APIs:
- Users:
- POST /users/ - Create/signup a new user
- POST /users/login - Login a user
- Posts:
- POST /posts - Create a new post
- GET /posts - View posts. Response of this requires pagination as it can contain even 1 million posts so the parameters can be:
- limit
- offset
- user_id (optional)
- GET /posts/post-id - View a post
- DELETE /posts/post-id - Delete a post
- Comments:
- POST /posts/{post-id}/comments - Create new comment
- GET /posts/{post-id}/comments - View post's list of comments
- GET /posts/{post-id}/comment/{comment-id} - View a comment
- DELETE /posts/{post-id}/comment/{comment-id} - Delete a comment
- Votes:
- POST /posts/{post-id}/vote - Upvote/downvote a post
- POST /posts/{post-id}/comments/{comment-id}/vote - Upvote/downvote a comment
- Images:
- POST /posts/{post-id}/images - Upload a image to a post body
- GET /posts/{post-id}/images/{image-id} - Get an image of post
- POST /posts/{post-id}/comments/{comment-id}/images - Upload a image to a comment body
- GET /posts/{post-id}/comments/{comment-id}/images/{image-id} - Get an image of a comment
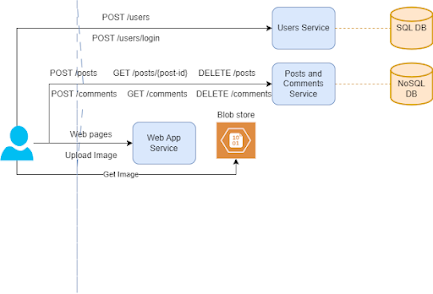
Step 2: Mapping functional requirements to architectural diagram:
1. Browser only application: For this we will have web app service which will serve static web pages.

2. User Sign up / login: We will have a user service and this service have its own DB to store user info which we can choose as SQL DB as it's going to be structured data and also its not going to be huge.

3. Create/Delete a post: Again for this we will have another microservice say post service which will have it's own DB. As these number of posts are going to be huge and also post schema, we may want to vary time to time, I am going to use Nosql DB for this.
Given we can upload an image in the post, we can use any blob store to save the imges so if the post contains the image, a request will go to web app service which will upload the image to blob store and then take the image-id and put it in the post body and send a request posts service to save the post
While viewing the post, first we will get the post content using the posts service and then when the browser sees the image url, it can directly fetch from the blob store using the url.

4. Posting comments / Deleting comments:
5. Comments are shown in list in descending order of posting time:
We can use a different microservice Comments with it's own DB but we can merge it with Post service and use the same DB. As you see comments are tightly attached to post and also their schema is almost same except comments will have a post id attached to it. We also need to add a timestamp fields as we need to show comments in sorted order.
We can opt for any approach but I am choosing to have one micro service for posts and comments and calling it Post and Comment service.
If you see we are also satisfying FR 6: Deleting posts and comments here.
We can just maintain a schema like folllows:
Post Id | count |
Comment Id | count |
But the problem with the above schema is
- We can't restrict user to just vote once for a single post/comment.
- FR 7: Can't get popular posts of last 24 hours.
That means we can't go wth the above schema. Hence here is the schema which I am proposing:
Post_id | User_id | Vote (+1 / -1) | Timestamp |
Comment_id | User_id | Vote (+1 / -1) | Timestamp |
With this we can at least achieve the functinalties including FR 7 too. We will see the performance part when we will address non functional requirements.
.png)
8: Home page contains the top popular posts: This is the most trickest functional requirement of this design. If you see the voting data is with Votes service and post content is with Posts service. Getting popular posts when the api call has been made could be very expensive. As this list is there in the home page, we can't risk of having delays in the page load.
To solve this issue we are going to use CQRS pattern. We are now going to introduce a Ranking microservice which will pull voting data from Votes service and post content from Post service. It then sort this data based on ranking and save this data into its own nosql DB. Now whenever the call for popular posts comes, it will be redirected to ranking service.
There are some consideration here:
- We know that the sliding window here is 24 hours so rankng service can query only the posts which are kind of active in this window.
- Given we don't have to show always the most recent data, we can use batch processing in the ranking service as this operation is heavy.
So here is what ranking service will do at a regular interval:
- Get the active votes from voting service for last 24 hours.
- Group the votes (upvotes - downvotes) by post_id.
- Sort the post_ids in descending order according to votes.
- Get the post content from POST service.
- Save it in the DB.

So above is the final design of our product which is satisfying all the functional requirements. Now let's move to non functional requirements.
Step 3: Mapping non functional requirements to architectural diagram:
1. Scalablity: Given we are talkng about millions of active users, a single instance of service won't work. Obviously we need to have multiple instances of every services and a load balancer to balance the traffic.
Another scalability issue here is the large data of posts and comments so we are going to shard the Post and comments data.
For posts we can use hash based sharding with hashing on post_id. I know this can be a bottlenect if we have to show all the posts from a particular user as posts might be distributed among multiple shards but this is not even our functional requirement. If it is added then we can still serve it and with little tweaks we can serve it effficiently.
For comments we can't shard based on comment_id as in general the comments will be fetched according to post_id and if you see if we go with comment_id, we might end up retrieving comments from different shards which is a big performance issue.
So what we can do is we can shard the comments based on post_id using hash based sharding. This will work well but it will create problem when a post become popular it starts having too many comments then what will happen that a particular shard will become too big and can become the scalability issue and also performance bottleneck.
To handle such issue we can use a compound key (post_id, comment_id) and we can apply range based sharding. If we use it, mostly we will get data from one shard or at most two shards.
In this way we can handle the scalability.
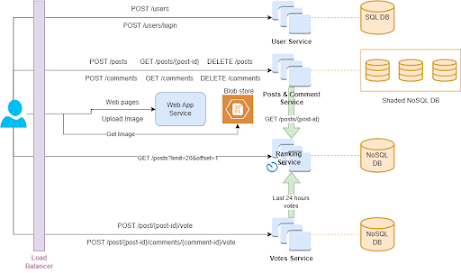
- Image load time can be greater while fetching from the blob store. To avoid that we can use CDNs where we can store images of popular posts. We can also use CDNs to serve the static html pages too.
- We can use cache to store the most popular posts and it's content in order to avoid traffic on GET requests of posts which are ultimately be directed to Posts service or Ranking service. Even the cache is not up to date, it is fine as we have chosen availability over consistency so eventual consistency is just fine.
- Index on post_id for post collection and compound index(post_id, comment_id) on comment collection really can help on speeding up the Get requests. We can do the similar indexing on other DBs too.
- Now another problem is, for a post/comment to load, we also need to show the upvotes and downvotes of the post or comment but votes data are there in Votes service DB so to load the post we need to call two microservice. We can take following steps to make it faster to fetch all post data or comment data including votes from one microservice only:
- Two fields will be added to post and comments collection schema:
- upvotes_count
- downvotes_count
- Queue the voting event from Votes service to Posts service so post service worker will fetch the events and can bulk update the DB with upvotes and downvotes count.

3. Availability: To achieve the availability we can replicate the databases and our services. We can also have our system running and replicated in different regions. This will also boost the performance.
4. Durability: We are already achiving the durability when we replicated the data accross regions. We can still periodically backed up our data to cheaper storage like S3 in order to have backups. This can also help us to cleanup old data from DBs to boost the performance if required.
Now that we have handled our every functional and non function requirements. Here is our final design:
.png)
That's all for this system design problem!
No comments:
Post a Comment